Last few days I'm feeling a bit like an archaeologist. It's probably a great story to explain to a newcomer just what's the importance of the internet, coupled with a great search engine. But I digress.
What follows is a pretty long post, covering a lot of ground in the graph reachability problem and transitive closures, enumerating various naive solutions (i.e., the ones you are likely to see used), then moving to much more promising approaches.
Introduction
Let's say you have a directed graph, G = (V, E), and you want to know real fast whether you can reach some node from some other, in other words whether there is a directed path u --> v, for any nodes u and v. (Take a moment to convince yourself that this is a trivial problem if the graph is undirected). Before we continue, lets stop and think where this might be useful. Consider a (really silly) class hierarchy (we also call it an ontology):

Testing whether there is a directed path between two nodes in a class hierarchy is equivalent to asking "is this class a subclass of another?". That's basically what the instanceof Java operator does (if we only consider classes, then subtyping in Java forms a tree - single inheritance, remember? - but if we add interfaces in the mix, we get a DAG, but thankfully, never a cycle).
Lets formally denote such a query by a function existsPath: V x V --> {1, 0}. It takes an ordered pair of nodes, and returns whether there is a path from the first to the second. Now, lets make sure that having such an existsPath function is, in fact, the characteristic function of the transitive closure of the graph, that is, given any edge, we can apply this function to it to test whether it belongs to the transitive closure or not, i.e., whether it is one of the following edges:

When we talk about transitive closure, though, we mean something more than merely being able to answer graph reachability queries - we also imply that we possess a function successorSet: V --> Powerset(V). i.e., that we can find all ancestors of a node, instead of checking if a particular node is an ancestor of it or not.
By the way, the above explanation is exactly the reason why in Flexigraph I define the interfaces (sorry, but blogger doesn't play very nicely with source code):
| public interface PathFinder { |
| boolean pathExists(Node n1, Node n2); |
| } |
| public interface Closure extends PathFindr { |
| SuccessorSet successorsOf(Node node); |
| } |
"Closure extends PathFinder" is basically a theorem expressed in code, that any transitive closure representation is also a graph reachability representation. That's the precise relation between these two concepts - I'm not aware of any Java graph library that gets these right. Continuing the self-plug, if you need to work with transitive closures/reductions, you might find the whole transitivity package interesting - compare this, for example, with JGraphT support, or yWorks support: a sad state of affairs. But I digress again.
Supporting graph reachability queries
Ok, lets concentrate now on actually implementing support for graph reachability queries. These are the most important questions to ask before we start:
- How much memory are we willing to spend?
- Is the graph static? Or update operation are supported (and which)?
Bit-matrix: The fastest reachability test is offered by the bit-matrix method: make a |V| x |V| matrix, and store in each cell whether there is a path from the row-node to the column-node. This actually materializes the transitive closure, in the sense that we explicitly (rather than implicitly, to some degree) represent it (and we already argued that representing the transitive closure also implies support for graph reachability queries).
Of course, this has some obvious shortcomings. Firstly, it uses O(|V| ^ 2) memory - but this is not as bad as it looks, and it would probably be a good solution for you if your graph is static. Which leads us to the second problem - it is terrible if you expect to frequently update your graph.
Adjacency-list graph representation: another way of representing the transitive closure is to just create an adjacency-list graph with all the edges of the transitive closure in it. In the example, that would mean to create a graph to represent the second image. (This is what JGraphT and yWorks offer - it's the simplest to implement). This has numerous disadvantages. First, this is a costly representation - such a representation is good for sparse graphs, but it is very easy for a sparse graph to have a dense transitive closure (consider a single path). Worse, if you represent each edge with an actual "Edge" object, then you are quite probably end up with a representation even costlier than the naive bitmap method - compare using a single bit to encode an edge vs using at least 12 bytes (at least, but typically quite more than that), i.e. 96bits. Also, this representation doesn't even offer fast reachability test - testing whether two nodes are connected depends on the minimum degree of those nodes, and this degree can be large in a dense graph. All in all, this representation is the lest likely to be the best for a given application.
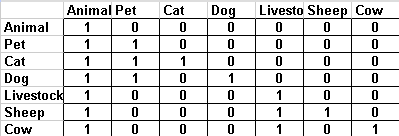
Agrawal et al: Now, lets see the approach in a very influential paper published in 1989: Efficient Management of Transitive Relationships in Large Data and Knowledge Bases. Lets see a figure from this paper, starting from the simple case of supporting reachability queries in a tree:

(Don't be confused by the edge directions, they just happened to drew them the other way around). Each node is labelled with a pair of integers - think of each pair as an interval in the X-axis. The second number is the post-order index of that node in the tree, while the first number is equal to the minimum post-order index of any descendant of that node. Lets quickly visualize those pairs as intervals:

As you can see, the interval of each node subsumes (is a proper superset of) the intervals of exactly its descendants. Thus, we can quickly test whether "e is a descendant of b" by asking "is 3 contained in the interval [1, 4]?", in O(1) time.
Quick check: does it easily support graph updates? No! Inserting a new leaf under node g would require changing the numbers of g and everything on its right (that is, all the nodes of the graph!). And we are still only discussing about trees. Lets see how this generalizes for acyclic graphs (this can be similarly generalized to general graphs, but I won't elaborate on that here). Again, a figure from the paper:
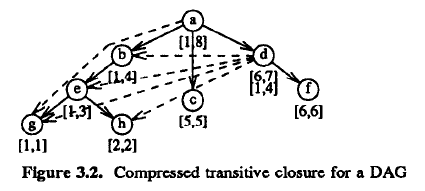
Second check: how does this cope with graph updates? Much worse! If, for example, we have to change the interval of g, we now must search potentially the whole graph and track where its interval might have been propagated, fixing all those occurrences with the new interval of g. Well, this sucks big time.
Now, lets try to justify the "historical accident" that the title promises. What if I told you that this problem was already solved 7 years earlier than Agrawal reintroduced it? More importantly, what if I told you that (apparently!) hardly anyone noticed this since then? It's hard to believe. For example, here is a technical report published recently, in 2006: Preuveneers, Berbers - Prime Numbers Considered Useful . Don't bother reading all those 50 pages - here is a relevant quote (shortly after having presented the Agrawal et al method - emphasis mine):
In the previous section several encoding algorithms for efficient subsumption or subtype testing were discussed. As previously outlined, the major concern is support for efficient incremental and conflict-free encoding. While most algorithms provide a way to encode new classes without re-encoding the whole hierarchy, they often require going through the hierarchy to find and modify any conflicting codes. The only algorithm that does not suffer from this issue is the binary matrix method, but this method is the most expensive one with respect to the encoding length as no compaction of the representation is achieved.This statement is the authors' motivation for design a new approach (a not too practical dare I say, requiring expensive computations on very large integers). They didn't know the solution.
Here is another example, published in 2004.Christophides - Optimizing Taxonomic Semantic Web Queries Using Labeling Schemes. This is a great informative paper surveying at depth a number of different graph reachability schemes, with a focus on databases. Christophides, actually, is my former supervisor, Professor at the University of Crete, and a good friend. Unfortunately, even though this paper actually cites the paper that contains the key idea, they also didn't know the solution (this I know first-hand).
Yet another example, published in 1999: Bommel, Beck - Incremental Encoding of Multiple Inheritance Hierarchies. Again, they didn't know the solution, so they ended up creating a more complicated, less-than-ideal work-around (see for yourself).
I don't even dare to look into all ~250 papers that cite Agrawal's work.
This is rather embarrassing. Before continuing, this kind of regression would have been highly unlikely if there was an efficient way (e.g. google scholar :) ) to search for relevant research. Here goes the obligatory memex link.
That being said, lets finally turn our attention to the mysterious solution that was missed by seemingly everyone. Dietz - Maintaining order in a linked list. This paper was published much earlier - in 1982, a year special to me since that's when I was born. Dietz introduces the (lets call it so) order maintainance structure, defined by this interface:
So how can this structure solve the incremental updates problem? Let's see Dietz' solution of the case of trees. Lets draw another tree.

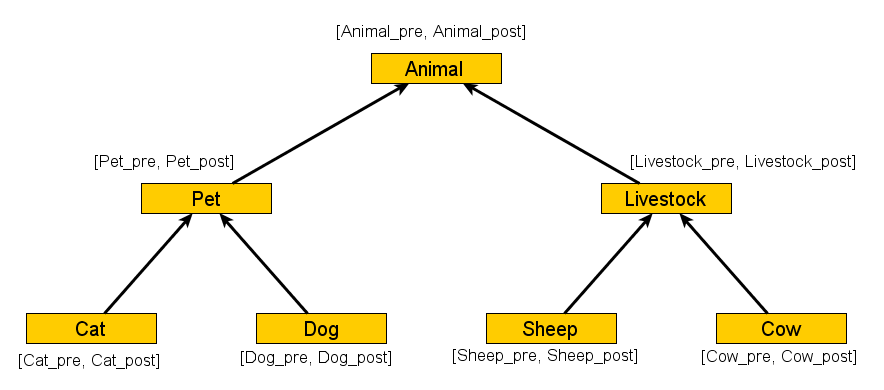
Okay, so this is the same tree, and I have labelled the nodes with intervals, with one catch - the intervals do not comprise integers, but symbolic names. What's the deal, you say? Here's the deal!

That's it! The colors are there so you can easily match-up the respective nodes. This is a linked list, or more precisely, the order-maintainance list. Any two nodes in it define an interval. For example, [Pet_pre, Pet_post] interval (green in the picture) subsumes both Cat's and Dog's nodes - precisely because it is an ancestor of both! Note that, internally, these list nodes do in fact contain integers that observe the total order (e.g., are monotonically increasing from left to right) so we can test in O(1) whether a node precedes another. This is quite a simple structure, and there are very good algorithms for inserting a node in it - if there is no space between the integers of the adjacent nodes, an appropriate region of this list is renumbered.
Update: probably it's obvious, but better be specific. So how do we add a descendant? Let's say we want to add a graph node X that is a subclass of Pet. We simply create two list nodes, X_pre, X_post, and insert them right before Pet_post. That would result in a chain Pet_pre --> [whatever nodes were already here] --> X_pre --> X_post --> Pet_post. Or we could add these right after Pet_pre, it's equivalent really. (As a coincidence, both Dietz and I chose the first alternative, to insert child_pre and child_post right before parent_post. I had a reason for this actually, there is a tiny difference because I'm using Integer.MIN_VALUE as a sentinel value, but that would be way too much details for this post). Of course, to insert a node, say B, between two others, say A and C, we have to find an integer between label(A) and label(C), i.e. to make sure that we have label(A) < label(B) < label(C), without affecting any existing label relation. If label(A) = label(C) + 1 (i.e., consecutive, no space between them for a new node), we have some nodes to make space at the place of insertion. Compare with Dietz' Figure 4.1, in the "Maintaining order in a linked list" paper.
While this might not seem such a big win for the case of trees, it is absolutely necessary in the case of graphs. This is what Agrawal et al missed! Instead of using integers directly, they should have used nodes of an order-maintainance structure. Why? Because when an interval does not have space to accommodate a new descendant, instead of widening the interval and then scanning the whole graph to find appearances of those integers to fix them, we instead make only local changes in the order maintainance structure in O(1), without even touching the graph!
You can visualize the difference in the following example.
 The segmented edges are non-tree edges, so they propagate upwards the intervals, thus, the H node ends up having 4 distinct intervals. Now, if instead of nodes such as E_pre and E_post, we had numbers (say, (5,6)), what would have happened if we wanted to add a descendant under E but it had no space in its interval? We would fix the boundaries of E's interval, and we would have to search the graph to see where the old boundaries have been propagated (i.e. in nodes F and H). With the order maintainance structure, this is not needed. We locally renumber whichever node is required, and we do it once - we only renumber E_pre and E_post once, and due to node sharing (instead of copied values/integers!), it doesn't matter where these might have been propagated, all positions are automatically fixed too! Contrast this to having to visit F, G and H, find E_pre, E_post in their intervals, and fix them in all places. Let alone if we had to renumber a series of intervals, and hunt the propagations of all of them in the graph, and so on...
The segmented edges are non-tree edges, so they propagate upwards the intervals, thus, the H node ends up having 4 distinct intervals. Now, if instead of nodes such as E_pre and E_post, we had numbers (say, (5,6)), what would have happened if we wanted to add a descendant under E but it had no space in its interval? We would fix the boundaries of E's interval, and we would have to search the graph to see where the old boundaries have been propagated (i.e. in nodes F and H). With the order maintainance structure, this is not needed. We locally renumber whichever node is required, and we do it once - we only renumber E_pre and E_post once, and due to node sharing (instead of copied values/integers!), it doesn't matter where these might have been propagated, all positions are automatically fixed too! Contrast this to having to visit F, G and H, find E_pre, E_post in their intervals, and fix them in all places. Let alone if we had to renumber a series of intervals, and hunt the propagations of all of them in the graph, and so on...
Just for completeness, this is what the order maintainance list would look like, in the last example:
A_pre --> B_pre --> C_pre --> D_pre --> E_pre --> E_post --> D_post --> F_pre --> F_post --> C_post --> G_pre --> G_post --> B_post --> H_pre --> H_post --> A_post.
In this structure we perform the renumbering, not in the graph! Particularly, in some (typically small) region that contains the two nodes inside which we want to insert something.
So, there you go. This is the trick I (re)discovered on some Friday of last March, and ended up coding http://code.google.com/p/transitivity-utils in the following weekend, which implements all of the above and more, so you don't have to. It is hard to believe that this went unnoticed for 20 years - and even harder to believe that the solution was there all along, waiting for someone to make the connection.
Now that's something to ponder about. Oh, and thanks, Dietz, great work!
If you managed to read all the way down to here, my thanks for your patience. That was way too long a post, but hopefully, you also earned something out of it. I regard this a very interesting story, and wish I was a better storyteller than this, but here you go. :)
- Insert(x, y)
Inserts element x right afterwards element y.
- Delete(x) (Obvious)
- Order(x, y)
Returns whether x precedes y.
So how can this structure solve the incremental updates problem? Let's see Dietz' solution of the case of trees. Lets draw another tree.
Okay, so this is the same tree, and I have labelled the nodes with intervals, with one catch - the intervals do not comprise integers, but symbolic names. What's the deal, you say? Here's the deal!

Update: probably it's obvious, but better be specific. So how do we add a descendant? Let's say we want to add a graph node X that is a subclass of Pet. We simply create two list nodes, X_pre, X_post, and insert them right before Pet_post. That would result in a chain Pet_pre --> [whatever nodes were already here]
While this might not seem such a big win for the case of trees, it is absolutely necessary in the case of graphs. This is what Agrawal et al missed! Instead of using integers directly, they should have used nodes of an order-maintainance structure. Why? Because when an interval does not have space to accommodate a new descendant, instead of widening the interval and then scanning the whole graph to find appearances of those integers to fix them, we instead make only local changes in the order maintainance structure in O(1), without even touching the graph!
You can visualize the difference in the following example.

Just for completeness, this is what the order maintainance list would look like, in the last example:
A_pre --> B_pre --> C_pre --> D_pre --> E_pre --> E_post --> D_post --> F_pre --> F_post --> C_post --> G_pre --> G_post --> B_post --> H_pre --> H_post --> A_post.
In this structure we perform the renumbering, not in the graph! Particularly, in some (typically small) region that contains the two nodes inside which we want to insert something.
So, there you go. This is the trick I (re)discovered on some Friday of last March, and ended up coding http://code.google.com/p/transitivity-utils in the following weekend, which implements all of the above and more, so you don't have to. It is hard to believe that this went unnoticed for 20 years - and even harder to believe that the solution was there all along, waiting for someone to make the connection.
Now that's something to ponder about. Oh, and thanks, Dietz, great work!
If you managed to read all the way down to here, my thanks for your patience. That was way too long a post, but hopefully, you also earned something out of it. I regard this a very interesting story, and wish I was a better storyteller than this, but here you go. :)
Nice post Dimitri.
ReplyDeleteI have some information you might find useful.
1) The two main papers you compare in this post had a different goal. In particular, the subject of "Dietz - Maintaining order in a linked list." is how to maintain the order of some elements upon updates. On the other hand, the working hypothesis of "Efficient Management of Transitive Relationships in Large Data and Knowledge Bases." was that data is static. Therefore, it was reasonable for the authors of the second paper to consider the first paper irrelevant.
2) The connection you do is a nice observation and really useful for main memory implementations. However, labeling schemes are extensively used inside databases, in particular when tree (XML) or DAG (RDFS) shaped data are stored in relational databases. In this context, you just can't manipulate pointers to list nodes. You could, if object-oriented databases were not dissapeared into oblivion (as you say in the subtitle of your blog:)) But with the standard relational database forget it. Therefore, I think it is not surprising that you were the first to make that connection. Most people working on labeling schemes have the objective of applying them inside a relational DB. I am not aware of any previous work on applying labeling schemes to answer reachability queries in main memory. But there migh exist without being so famous, or so many.
3) There exists a theoretical work ( Labeling dynamic XML trees ) with really nice resuts regarding the trade-off between the tolerance of a labeling scheme to updates and the size in bits of the labels it produces. In this paper, labeling schemes were devided into two categories w.r.t. how they treat updates, namely Immutable labeling schemes that do not need any relabeling after updates as opposed to dynamic labeling schemes that need to relabel a part of the graph.
It is proven in the paper that the worst case for the size of labels is Theta(N) for any immutable labeling scheme, where N is the number of nodes!
Consider now the case of the interval labeling scheme. You can treat it as both immutable and dynamic with a small but important variation. If you consider that pre and post integers can have arbitrar length, then there is no need for relabeling at all. Imagine for instance a world that real numbers (this is the meaning of "integers can have arbitrar length") can be represented in a machine. Then you could always find a number between any two given!
The variation of the interval scheme that you show, restricts the length of the integer used as pre and post in the size of the machine (lets say 32 bits). Under this restriction, the scheme is not immutable any more: relabeling might be needed.
4) Amortized analysis is not my favourite. On the contrary, it usually reflects that inability of ours to understand (and therefore to analyze) the properties of some algorithm. Therefore, there is a wide range of misunderstanding you can hide in an amortized analysis. However, by a practical viewpoint, if the experimenatal studies shows it works, then it's ok.
Thanks for your comment Kritia! ;)
ReplyDelete1) The whole 4th section of Agrawal's paper deals with incremental updates (tree edge insertion, non-tree edge insertion, tree edge deletion, non-tree edge deletion). Sure, it looks unfinished and hasty work, but since they put it in, I think I am justified to say that this was something that mattered to them!
2) This is a very interesting issue I glossed over. Linked lists mostly require random access memory, which is at odds with databases where we mostly want linear access. So what's the best way to model a linked list in a database? My first try would be a B+tree, and to perform ancestor queries I would have to join the graph nodes with this table. This should be small though, just few bytes per graph node, but I would hope most of it could reside buffered in main memory.
3) Interesting paper, thanks. The result you describe feels quite intuitive. (Graph updates we mean insertions I guess - I also forgot to mention in my post that deletions are not supported).
O(N) labels per graph node are rather many, especially if these are copied into, instead of referred from, the node, even more if these are unbounded. I'm not sure that such protective measures are necessary. Even with 62 bits (I couldn't employ all 64 bits of a long for this purpose), actual need for renumberings is rare, and I would imagine even more rare if one used double that space.
And it's not like we need huge labels, even with 62 bits I can fit tons of things, with double that size, I doubt anyone would have a data set to overflow it.
I vaguely recall one author once claiming that using actual machine-word-based reals would solve the problem, without realizing that this would require infinite precision :)
4) O(1) amortized models well that "in most cases, you will find space. In the rare cases that you won't" (and with 62 bits, one has to reach *deep* hierarchies to vanish a gap) "the algorithm fixes this quickly (O(1) per previous operation since last renumbering) and makes sure this won't happen soon again". I don't have any issues with that. If I was building a real time medical machine, I might be skeptical, or if we are talking about persistent, rather than ephemeral, structures.
Cyclic graph nodes cannot be labeled in a total order. The proposed algorithm works for DAGs
ReplyDeleteObviously any cyclic digraph can have its strongly connected components (SCCs), identified and collapsed, leaving the resulting graph as a DAG. And this is how most reachability algorithms work anyway for general graphs, reduce to DAG then deal with the DAG reachability.
Delete